By J. Philippe Blankert, 16 February 2025
Large Language Models (LLMs) can continuously learn and get smarter by leveraging more data, better algorithms, ongoing training, and human feedback. Over time, this leads to an increase in their apparent “intelligence.” Below, we break down how this happens in theory and practice, using clear examples and analogies.
More Data, Better Algorithms, More Compute: Why Bigger is Often Smarter
Scale of Training – In general, the more data you train a language model on and the larger you make the model (more parameters), the better it performs. Researchers have found clear scaling laws showing that as you increase model size, dataset size, and computational power, the model’s performance (measured by error rates or “loss”) improves following a predictable trend.
In simple terms, a bigger brain with more knowledge tends to do better. For example, OpenAI’s GPT-3 model (175 billion parameters) was about 100× larger than its predecessor GPT-2 and showed a big jump in abilities like answering questions and doing translations without task-specific training
Google’s PaLM model (540 billion parameters) similarly found that as the scale of the model increases, performance improves across tasks and even unlocks new capabilities
This is akin to a person learning more from reading vast libraries of books – with enough information and a large enough “brain,” new skills can emerge.
Better Algorithms – It’s not just raw size; algorithmic improvements make a huge difference. A prime example was the switch to the Transformer architecture in 2017, which “radically changed the landscape of NLP by discarding recurrence and convolutions in favor of self-attention”
This new architecture could learn long-range dependencies in text more effectively, leading to large boosts in language understanding. In other words, a better design for the “brain” made learning easier. Subsequent refinements to training algorithms (optimization methods, regularization, etc.) also improved stability and efficiency
For instance, more advanced optimizers (like Adam) adjust learning rates on the fly and help train very deep networks faster than older methods, allowing models to reach higher accuracy. Improved algorithms are like better study techniques – if you learn how to learn more efficiently, you end up smarter for the same amount of effort.
Increased Compute – Lastly, having more computational power (faster GPUs, TPUs, more processors in parallel) enables training these huge models on huge data. If data and model size is like the curriculum, compute is like the time spent studying. Big breakthroughs in LLMs often coincided with leaps in compute availability; more compute lets the model see more examples and try more sophisticated updates to its parameters. In practice, researchers orchestrate thousands of chips in parallel to train cutting-edge models
Higher compute also allows running experiments to tune hyperparameters or try novel architectures, which can yield algorithmic improvements. All together – scale, algorithms, and compute – form the core theory: give the model a lot of high-quality information, a good way to learn from it, and the horsepower to do so, and it will improve.
Continuous Learning Methods in AI
LLMs traditionally are trained once on a fixed dataset (called offline training). However, to continuously learn and improve, AI researchers use techniques that allow models to update and adapt on an ongoing basis. This field is often called continual or continuous learning. Here are some key methods:
Reinforcement Learning (Learning by Rewards)
Reinforcement Learning (RL) lets an AI agent learn by trial and error in an environment. The idea is similar to training a pet: the agent takes an action and gets a reward or punishment signal, then adjusts its behavior to get more rewards in the future. As one source puts it, “Reinforcement Learning is the study of agents and how they learn by trial and error. It formalizes the idea that rewarding or punishing an agent for its behavior makes it more likely to repeat or avoid that behavior in the future.”
Over many cycles, the AI reinforces behaviors that work well (yield high reward) – hence the name.
For LLMs, pure RL isn’t directly applied in pre-training (since that’s usually done with static text data), but it becomes important in fine-tuning and certain tasks. For example, an LLM can be put in an interactive setting (like a dialogue) and use RL to learn responses that maximize a reward (which could be user satisfaction or some performance metric). A famous success of RL in another domain is DeepMind’s AlphaGo, which learned to play Go at superhuman level by playing millions of games against itself, continuously improving its moves via rewards (win/lose outcomes). The key point: RL allows continuous improvement by interacting with an environment and learning from feedback, rather than just learning from a fixed dataset.
Online Learning (Learning on the Fly)
In online learning, a model updates itself incrementally as new data comes in, rather than waiting for a batch retraining. This is like learning on the fly, or a student that updates their knowledge after each new lesson instead of only at semester’s end. Formally, online machine learning is a method in which data becomes available in a sequential order and is used to update the predictor at each step, instead of training just once on a fixed dataset
For an LLM, this could mean continuously ingesting new information (news, new writings) and refining its weights so it stays up-to-date. It’s challenging because the model must avoid catastrophic forgetting (losing old knowledge when new info arrives). Techniques like incremental learning or rehearsal (reviewing a mix of old and new data) are used to address that. Online learning is essential in situations where data is streaming (e.g. real-time sensor data or continuously updated text corpora). For example, a language model serving as a personalized assistant might update itself with a user’s new emails to better understand their writing style over time. This continuous update process keeps the model’s knowledge fresh and tailored, essentially allowing lifelong learning.
Self-Distillation (Learning from Itself)
Self-distillation is a technique where a model teaches itself using its own internal knowledge. In knowledge distillation, typically a smaller “student” model is trained to mimic a larger “teacher” model. In self-distillation, the twist is that the model plays both roles – it learns from its own earlier predictions or from deeper layers to improve the shallower layers. Essentially, the model tries to distill the knowledge it has gained into a more efficient form within itself.
One way to imagine this: think of an author who writes a rough draft (complex and verbose) and then writes a concise summary of it for themselves – the summary captures the essence in a simpler form. Similarly, a neural network can use the outputs of later layers or previous training epochs as “soft targets” for earlier layers or current epoch, gradually refining its understanding. Research has shown that self-distillation can surprisingly improve a model’s performance without any new external data
It’s like a student revising their own notes and clarifying them, getting a better grasp of the material in the process.
Meta-Learning (Learning to Learn)
Meta-learning is often described as “learning to learn.” Instead of learning a single task, the model learns how to rapidly adapt to new tasks. A meta-learning system might train over many small tasks so that it can quickly pick up a new task with only a few examples (this is also called few-shot learning). One researcher described it as a key step toward agents that can “continually learn a wide variety of tasks throughout their lifetimes.
In other words, the AI gains the knack of adapting itself, much like a human who learns general study skills that can be applied to any subject.
A popular example is the MAML (Model-Agnostic Meta-Learning) algorithm, which trains a model’s initial parameters such that they can be fine-tuned to a new task very quickly with just a few training steps. For LLMs, meta-learning abilities often emerge at scale – for instance, GPT-3 showed the ability to do new tasks from just a description or a couple of examples (it “meta-learned” during training how to follow instructions). Meta-learning research aims to make AI more flexible and adaptable, so it doesn’t need a huge retraining for every new problem. It’s akin to having a versatile skillset: instead of memorizing one procedure, the model figures out how to learn any procedure efficiently.
AI Self-Improvement Techniques
Beyond those foundational methods, there are specific techniques that allow an AI to improve itself using data or feedback it gathers. Think of these as the AI proactively getting smarter:
- Self-Training (Semi-Supervised Learning): In self-training, an AI uses its own predictions to train further. For example, imagine we have a lot of unlabeled text data. The model can label this data itself (with the predictions it currently makes, often called pseudo-labels) and then retrain on those labels to improve. This bootstrapping process can gradually enhance the model’s accuracy. It’s like a student testing themselves with practice questions: even without answers given, the student can guess an answer and then check consistency with what they know, refining their knowledge. Self-training has been successful in scenarios where there’s a small labeled dataset and a large unlabeled dataset – the model harnesses unlabeled data to improve its performance
Essentially, the model says “I’m fairly sure about these new examples, so I’ll treat my guess as truth and learn from it.” Over time, and with safeguards to avoid reinforcing errors, this can significantly boost the model’s capabilities.
- Active Learning (Asking for the Right Data): Active learning is a strategy where the model actively chooses which data points would be most useful to learn from next. Instead of passively learning from whatever data we have, the model can query an oracle (usually a human annotator) for labels on examples it finds confusing or informative. “Active learning is a technique where the machine decides which are the most important data points to be labeled by humans.”
By doing so, an AI can achieve more learning with fewer labeled examples – it focuses effort on the most informative cases. In practice, an LLM (or any model) might scan a large pool of unlabeled text and select sentences where it’s least certain about the next word, then ask a human or a trusted process for the correct answer. This is akin to a student who doesn’t ask about everything, but only about the homework problems they couldn’t solve – making efficient use of the teacher’s help. Active learning thus continuously guides the training process to areas that will maximally improve the model.
- Fine-Tuning with User Feedback: An extremely important way LLMs improve is by learning from user feedback. This means taking insights from how users rate or correct the AI’s responses and fine-tuning the model on that information. For instance, if users repeatedly correct an AI’s incorrect answer or mark certain responses as unhelpful, those interactions can be collected as training data. The model can then be updated (via further training) to prefer the corrected answers or to avoid responses that users disliked. Over time, this feedback loop makes the AI more aligned with what users actually want. If you’ve ever noticed an autocomplete or voice assistant get better as you use it (adapting to your vocabulary or preferences), that’s fine-tuning on user feedback in action. This approach overlaps with the next section (human-in-the-loop methods), and in practice is implemented through techniques like RLHF or direct fine-tuning on rated examples. A notable example is OpenAI’s InstructGPT, where human feedback was used to fine-tune GPT-3, making even a smaller model output preferred answers over a much larger original model.
Human-in-the-Loop: Combining AI and Human Feedback
Humans play a crucial role in teaching AI systems – hence “human-in-the-loop” learning. Rather than the AI learning completely on its own, a cycle is set up where humans guide the learning process at key points. This makes the AI’s improvement more directed and often safer or more aligned with human values.
Reinforcement Learning with Human Feedback (RLHF)
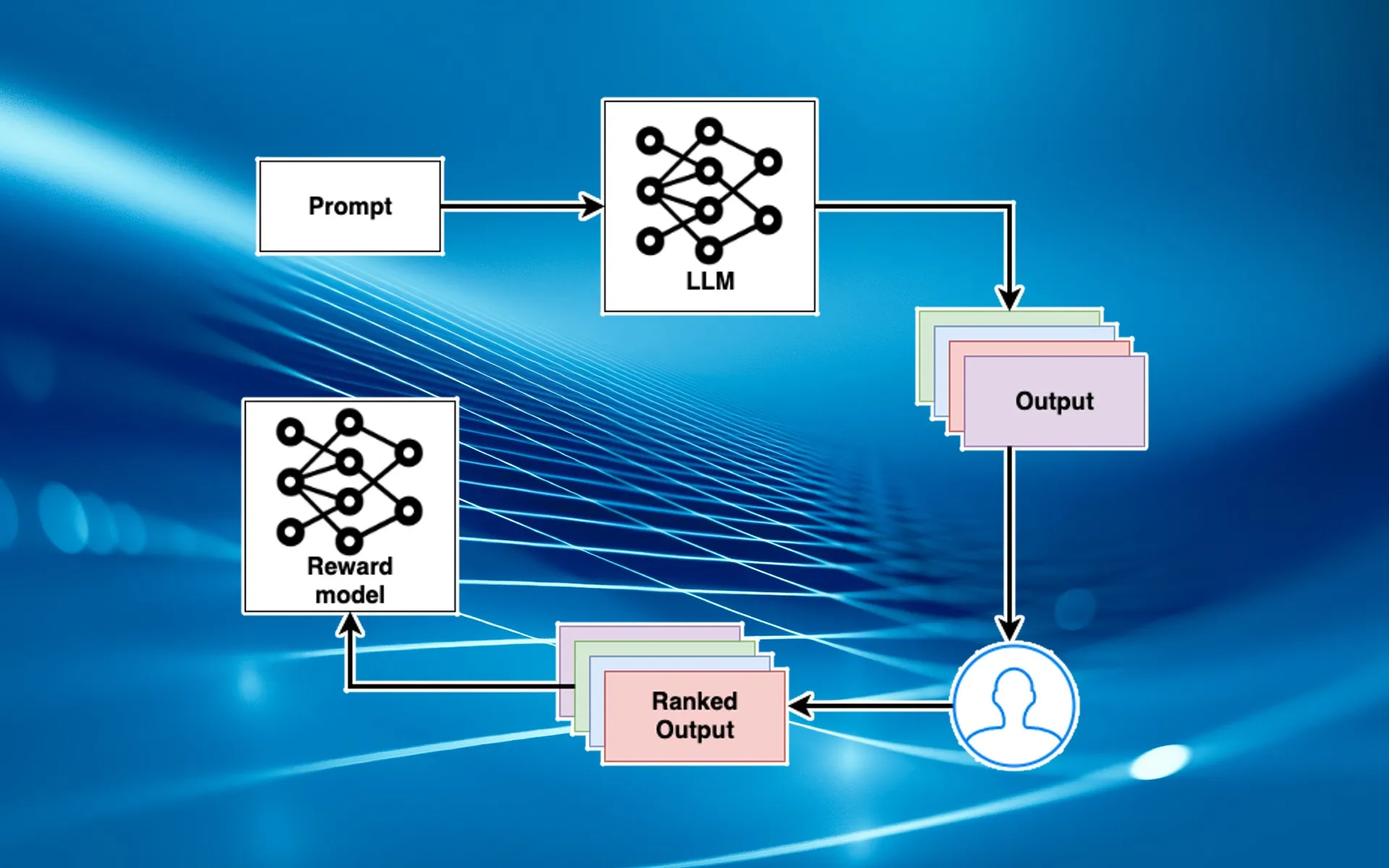
One powerful human-in-loop method is Reinforcement Learning from Human Feedback (RLHF). This is a special application of reinforcement learning where, instead of a numerical reward from the environment, the “reward” comes from human judgments. In practice, it works like this: the language model generates several possible outputs for a prompt; human reviewers rank these outputs from best to worst; the model then gets fine-tuned to produce outputs that would score higher according to a learned reward model derived from those rankings.
Essentially, humans are teaching the AI what kinds of responses are preferred.
RLHF was used to train InstructGPT (and later ChatGPT), which dramatically improved the helpfulness and politeness of GPT-3’s outputs. The results were impressive: a 1.3 billion-parameter InstructGPT model (after RLHF fine-tuning) was preferred by people to the original 175 billion-parameter GPT-3 on a wide range of tasks
This shows how effective human feedback can be – it’s not just about making the model polite, it actually made the smaller model better at understanding intent than a raw model 100× its size. RLHF is like training a clever student with an tutor: the student writes an essay, the tutor grades it and explains which parts are good or bad, and the student revises accordingly. Over many rounds, the student’s essays get dramatically better aligned to what the tutor expects. In the same way, RLHF aligns AI behavior with human preferences and values, by explicitly incorporating human judgments into the training loop.
Crowdsourced Data Annotation
Another human-in-the-loop approach is using crowdsourced workers to label data at a large scale. Modern AI often relies on enormous labeled datasets – for example, millions of examples of correct translations, or billions of words of text with certain annotations. Obtaining such data is a massive undertaking, and that’s where crowdsourcing comes in. Crowdsourced data annotation means enlisting a large number of people (often via the internet) to each label or verify a portion of the data
Projects like ImageNet, which was pivotal for computer vision, were built by crowdworkers labeling tons of images. For language models, crowdsourced workers might be asked to rate the quality of responses, to flag toxic content, or to categorize and transcribe text.
This approach leverages the fact that while any single person can only label a limited amount, many hands make light work – platforms like Amazon Mechanical Turk allow thousands of people to contribute to an AI’s training data. The diversity of annotators also helps incorporate varied perspectives, reducing bias. However, it requires careful quality control (to handle inconsistent or low-quality annotations). When done right, crowdsourcing provides the high-quality, rich datasets that fuel the initial training and fine-tuning of LLMs. It literally injects human knowledge and evaluation into the model’s learning process. In essence, it’s a way for humans to teach the AI at scale, by preparing the “textbooks” (labeled examples) that the AI studies. As one article noted, “crowdsourcing data annotation taps into a diverse pool of contributors to label data accurately and efficiently,” enabling the handling of vast datasets needed for intelligent systems.
Real-World Examples of Improvement: GPT, PaLM, and LLaMA
To make this concrete, let’s look at how some well-known LLMs have improved over successive generations and with the techniques above:
GPT Series (OpenAI)
OpenAI’s GPT (Generative Pre-trained Transformer) series is a prime example of intelligence growth in action. GPT-1 (2018) was the first model that showed the power of the Transformer on a large text corpus, but it was relatively small (117 million parameters). GPT-2 (2019) jumped to 1.5 billion parameters and was trained on far more data; as a result, it could generate much more coherent and fluent text. The improvement from GPT-1 to GPT-2 shocked many with how well the model could produce paragraphs of sensible, relevant text – essentially showing scaling up data and parameters made the model notably smarter.
The leap to GPT-3 (2020) was even more dramatic: at 175 billion parameters and trained on hundreds of billions of words, GPT-3 displayed few-shot learning. This means without explicit training for a specific task, GPT-3 could be prompted with a couple of examples and then perform the task at a strong level. As the GPT-3 paper title says, “Language Models are Few-Shot Learners” – a capability that smaller models didn’t really have. For instance, GPT-3 could translate or do Q&A when simply given a prompt like “Q: … A: …” a few times. This emergent ability came directly from the increased scale: the general theory was validated that more knowledge and a bigger network gave rise to qualitatively new skills. However, GPT-3 still would sometimes produce irrelevant or incorrect answers because it was only trained to predict text, not to follow instructions.
By early 2022, OpenAI introduced InstructGPT, which was essentially GPT-3 fine-tuned with human feedback (using RLHF as described). This made the model much better at understanding what users mean and want. Impressively, the tuned 1.3B version outperformed the untuned 175B version in human evaluations. Finally, GPT-4 (2023) took another leap by incorporating multimodal abilities (it can accept images as input) and further increasing model size (exact size not publicly stated). GPT-4 is better at reasoning, more factual, and less prone to go off the rails than GPT-3, thanks to a combination of more data, more compute, and extensive fine-tuning (with human feedback and other techniques). Over the GPT series, we see how each generation became more intelligent: from raw increases in scale (GPT-2 and GPT-3) to algorithmic and alignment improvements (InstructGPT and GPT-4). Each time, the model was able to handle more complex instructions and nuanced tasks – demonstrating continuous learning and improvement in practice.
Google’s PaLM
Google’s PaLM (Pathways Language Model), unveiled in 2022, is another great example. PaLM has 540 billion parameters and was trained with Google’s Pathways system, which allowed it to efficiently utilize a huge amount of compute across thousands of TPUs. The result was a model that achieved state-of-the-art performance on 29 of 29 NLP tasks in a few-shot setting, surpassing prior models on many benchmarks. Not only was PaLM highly competent in English, but it also showed strong performance in multilingual tasks and even reasoning problems that involve multiple steps (like logical puzzles or math word problems). PaLM’s improvement over earlier models camefrom scaling (it was larger and trained on more data than previous Google models like Gopher) and from training on a diverse dataset (text from websites, books, dialogues, code, etc.).
Interestingly, PaLM demonstrated some emergent abilities due to its scale – for example, it could explain jokes or solve simple arithmetic word problems, tasks that smaller models struggled with. Google researchers noted that PaLM’s performance grew predictably with model size and that some capabilities only kicked in at a certain scale, reflecting the scaling law concepts discussed earlier.
In summary, PaLM became one of the “smartest” language models of its time by pushing the frontier on data+model size and training efficiency. It’s a real-world proof that if you pour in enough data and compute with a good architecture, you get a notably more intelligent model at the other end.
Meta’s LLaMA
Meta (Facebook) took a slightly different approach with LLaMA (Large Language Model Meta AI), introduced in 2023. Rather than simply making the biggest model ever, the focus was on efficiency and accessibility. The LLaMA models range from 7B to 65B parameters – much smaller than GPT-3 or PaLM – but they were trained on an extremely large amount of text (trillions of tokens) using only publicly available data
The surprise was that LLaMA-13B (13 billion params) actually outperformed OpenAI’s GPT-3 (175B) on most benchmarks, and LLaMA-65B was competitive with other state-of-the-art models like PaLM-540B. This showed that data quality and training efficiency can make a smaller model punch above its weight. In other words, by using a carefully curated dataset and enough training steps, they squeezed more knowledge into each parameter of LLaMA.
LLaMA’s improvement story highlights a few things: (1) Algorithmic improvements – they likely used optimized training techniques (learning rate schedules, etc.) and architecture tweaks to maximize performance. (2) Scaling “smart” vs “brute force” – instead of just scaling up parameters, they scaled up training data efficiently, aligning with the idea of compute-optimal training (as suggested by the Chinchilla scaling law, which posits an optimal balance of model size and data size for a given compute budget). The outcome is an AI model that is highly capable but much easier to run on common hardware than a 500B monster model. LLaMA was made open to researchers, and almost immediately, people fine-tuned it with instruction data (often via RLHF or supervised instruction-following data) to create chatbots that approach the quality of ChatGPT – all with a relatively smaller model. This real-world case shows that continuous improvement isn’t only about making the model larger; it’s about making it better – either through scale or better training methods. In essence, LLaMA got “smarter” not by growing in size beyond predecessors, but by learning more efficiently from a huge trove of information.
Key Factors in Increasing AI Intelligence
From theory and practice, we can summarize some key factors that maximize an AI model’s growth in intelligence:
- Scaling Laws and Model Size: Simply put, bigger models trained on more data tend to perform better. There is a power-law relationship where error generally decreases as you scale up, albeit with diminishing returns. Importantly, recent research refined this by showing that it’s critical to also scale data with model size (a balanced growth). If a model is too big for the amount of data, it won’t reach its potential. Following these scaling laws – sometimes referred to as following the “compute-optimal” path – has been key to building frontier models. For example, the jump from GPT-2 to GPT-3 was a direct application of scaling laws, resulting in a huge capability gain.
- Data Quality and Diversity: The quality of training data is just as important as quantity. Feeding an LLM more data only helps if that data is rich and relevant. High-quality, diverse data exposes the model to varied language use and facts, making it more robust and “knowledgeable.” Conversely, poor or biased data will teach the model bad habits or incorrect information, leading to an AI that might be fluent but wrong or toxic.
A phrase often heard is “garbage in, garbage out.” To maximize intelligence, training data is carefully filtered and mixed from many sources (books, encyclopedias, code, dialogues) to cover a wide knowledge base. Data quality work (removing duplicates, fixing errors, balancing topics) might not be flashy, but it dramatically improves how well the model understands and generalizes. As one blog noted, the relationship between data quality and an LLM’s effectiveness “cannot be overstated”, since biased or narrow data will limit the model’s real-world performance.
- Optimization and Training Techniques: How you train the model – the optimization process – makes a difference in the final intelligence. Advancements like better optimizers (e.g., Adam, Adafactor), regularization techniques (to avoid overfitting), and training schedule (learning rate decay, curriculum learning) can each boost performance a bit. Even choices like how to initialize the weights or how to shuffle the data can matter for very large runs. There have been cases where simply training for longer or with a clever schedule yielded surprising improvements in reasoning ability. Additionally, techniques like curriculum learning (starting with easier tasks/data then gradually increasing difficulty) can lead to better comprehension, much like a student learning basics before tackling advanced topics. All these fall under making the training process more effective at implanting knowledge. For large models, stability is also a concern (avoiding divergence during training), so techniques like gradient clipping or scaling, and mixed-precision training (which speeds up training using 16-bit floats), help keep the model on track.
In summary, the smarter the training procedure, the smarter the resulting model – the community’s collective improvements in these techniques over years are one reason today’s LLMs are far better than those a decade ago.
- Multimodal Learning: Humans learn not just from text, but from seeing, hearing, etc. Similarly, AI models can be made to learn from multiple modalities (text, images, audio, video), which can enrich their understanding. A multimodal model, like GPT-4 which can process images and text together, has a broader context for reasoning. For instance, it can connect a description in words to an actual image, leading to more grounded understanding. Multimodal learning can unlock advanced reasoning because the model isn’t in a text-only bubble. One benefit noted is that such models “gain a better understanding of different types of situations” by processing varied sources. For example, if an AI learns the concept of “a cat” from images and from text, those reinforce each other – the visual modality teaches what a cat looks like, while text might teach abstract facts about cats. This cross-pollination makes the overall model more robust and versatile. In terms of intelligence growth, adding modalities means adding new knowledge and new ways to learn relationships (like connecting an image to a caption). The trend is moving toward AI that can jointly learn from text, images, audio, etc., which more closely reflects how we humans learn (we read, observe, listen, and so on). This is seen as a path to more general intelligence in AI.
Neural Architecture Search and Model Compression
Aside from training and data, researchers also work on improving the architecture and efficiency of models, so that AI can become smarter and more efficient at the same time.
Neural Architecture Search (NAS)
Designing the best neural network architecture by hand can be very complex. Neural Architecture Search (NAS) is an approach where the design of the neural network itself is automated – essentially, an algorithm searches through many possible network designs to find one that gives the best performance. It’s like having an AI help invent a better AI brain. NAS can discover architectures that humans might not have considered, or tune the number of layers/neurons in each part of the model for optimal learning. This technique has already led to innovations in image recognition models (like Google’s NASNet and EfficientNet were found by architecture search). In the context of LLMs, NAS could help find the most efficient layout of attention layers, feed-forward dimensions, etc., to maximize accuracy for a given model size or to make the model faster without losing ability.
For example, NAS might determine that a certain smaller layer can be removed or a certain connectivity pattern yields the same accuracy with fewer parameters. As noted in one article, “recent advances like neural architecture search can be employed for designing an optimal model architecture” for a given task. By doing this, we make the model smarter per unit of complexity – that is, a NAS-designed network might achieve higher performance than a manually-designed network of the same size. This is especially useful for continuous improvement because it means each new generation of model might not just be larger or trained longer, but could also be innately better structured for learning. It’s akin to evolving better brain structures over time. NAS is compute-intensive (it’s essentially trial-and-error over many architectures), but the payoff is a more efficiently intelligent model.
Model Compression Techniques (Distillation and Pruning)
It might sound counterintuitive, but sometimes making a model smaller can make it better in practical ways – this is where model compression comes in. Techniques like knowledge distillation and pruning aim to reduce the size or complexity of a model while preserving its intelligence. This is crucial for deploying models in the real world (on phones or browsers) and can also aid continuous learning by simplifying models so they train faster or adapt quicker.
- Knowledge Distillation: Think of a large model as a teacher and a smaller model as a student. In knowledge distillation, we have the big “teacher” model run on lots of inputs and produce outputs or “soft targets” (like probabilities for each answer). We then train the smaller “student” model to match the teacher’s behavior. Amazingly, the student often ends up almost as good as the teacher, even though it has far fewer parameters. It’s as if the large model’s knowledge got compressed into the small model. This works because the teacher’s outputs contain extra information (not just the correct answer, but how it would distribute probabilities among all options, which conveys what it thinks is similar or different). By learning to imitate that, the student model captures a lot of the teacher’s generalization ability. As one source explains, knowledge distillation “distills” the knowledge in a complex model into a smaller model that is much easier to deploy without significant loss in performance. This technique has been used to make lightweight versions of big LLMs that can, for example, run on mobile devices or respond faster, all while retaining most of the smarts.
- Pruning and Quantization: These are like spring cleaning for neural networks. Pruning removes neurons or weights that contribute little to the model’s decisions (perhaps their values are almost always zero or they’re redundant). By cutting out this “dead weight,” the model becomes smaller and faster, but if done carefully, it “enhances efficiency without significantly compromising performance.” It’s similar to trimming unnecessary branches from a tree so that resources are focused on the fruitful parts. Iterative pruning followed by a bit of retraining can often reduce a model’s size by 50% or more with only minor accuracy loss. Quantization, on the other hand, makes the computations leaner by using lower precision numbers (e.g., 8-bit integers instead of 32-bit floats to represent the model’s weights). This doesn’t exactly make the model “smarter,” but it makes it more efficient – which indirectly helps in deployment and scaling. A more efficient model can be trained on more data or used in more contexts, contributing to its overall utility.
By employing NAS and model compression, AI researchers ensure that improvements in intelligence don’t always come with prohibitive costs. An AI model that’s both smart and efficient can be iteratively improved (you can experiment more when it’s cheap to run) and can reach end-users, whose interactions can then provide further learning signals. In summary, NAS finds better brains, and compression creates leaner brains – both contribute to the continuous improvement loop of modern AI.
References:
- Kaplan et al., Scaling Laws for Neural Language Models – showed model performance follows power-law improvements as models and data scale
- Brown et al., Language Models are Few-Shot Learners (GPT-3 paper) – demonstrated that a 175B model can perform many tasks with minimal examples, validating the effect of massive scale
- PaLM (540B) by Google – achieved state-of-the-art few-shot results by scaling model size and training on diverse data.
- Touvron et al., LLaMA: Open and Efficient Foundation Models – showed a 13B model can outperform a 175B model by training on more tokens and better data.
- Finn, 2017, BAIR blog on Learning to Learn – discusses meta-learning as a path to agents that can learn many tasks over time
- Reinforcement Learning: OpenAI Spinning Up – “RL is learning via trial and error with rewards”
- Online Learning: Wikipedia – defines online learning as updating the model with each new data point sequentially
- Self-Distillation: Neptune AI blog – describes how a model can use its own knowledge to train itself (teacher and student are the same model)
- Active Learning: Saiwa.ai blog – “the machine decides which data points are most important to be labeled by humans”.
- RLHF: Ouyang et al. 2022 (InstructGPT) – fine-tuning GPT-3 with human feedback made it far more aligned; a 1.3B model with RLHF was preferred over a 175B model without it.
- Crowdsourcing: Sapien.ai blog – defines crowdsourced data annotation and its benefits for AI training.
- Transformer Improvements: Eventum AI blog – notes the Transformer (Vaswani et al. 2017) revolutionized NLP by enabling much better performance through self-attention
- Data Quality: Algomox blog – explains that poor-quality or biased data can make even a big model fail, highlighting the need for clean, diverse data
- Knowledge Distillation: Hinton et al. 2015 – introduced the idea of distilling knowledge from a large model to a small model.
Model Pruning: Datature blog – “removing unimportant parameters to improve efficiency without much performance loss”.